中国AI算力爆发!西部建“数字三峡”,上海打造“AI发电站”
本篇正文内容如下:
最近刷到个数据挺震撼:截至2024年,咱们国家的算力总规模已经超过280 EFLOPS(简单说就是算力单位,数值越大越能打),稳居全球第二。
更猛的是智能算力——就是专门给AI用的算力,已经飙到90 EFLOPS,占比超30%,比2019年翻了快13倍,平均每年涨90%。
一、AI算力基建,到底在搭什么“骨架”?
首先得明确,AI算力不是单指某一台服务器,而是一整套“国家级基建”——从数据中心到网络,再到怎么调度资源,有点像“AI时代的水电网”。
现在咱们国家的思路很清晰,就是“国家定方向+地方自己干+智能算力优先铺”。

最核心的就是“东数西算”工程,这事儿应该不少人听过,但具体咋回事?其实很实在:东部地区(比如长三角、粤港澳)AI需求猛,但是能源紧张、算力不够用;西部(贵州、内蒙古这些地方)水电风电多,成本还低。
所以国家在这8个地方建了“国家算力枢纽”,相当于把东部的“数据活儿”搬到西部去算,既省钱又环保,现在已经形成了“核心枢纽带头,各个区域配合”的网络。
举个直观的例子:北京、上海、广州这些地方,已经建了不少大型智算中心,专门给本地的AI企业、互联网公司做支撑——比如训练个大模型、跑个智能推荐,都得靠这些中心。
全国现在在用的算力中心机架,已经有830万标准机架,相当于830万个“算力储物柜”,装着各种能给AI供能的设备。
二、为什么现在AI算力突然“火出圈”?
不是凭空冒出来的热度,而是政策、技术、产业、商业模式这四个方面,刚好凑到了一起。
1. 政策给足了“定心丸”
国家层面早就把算力当成“新基建”的关键,除了“东数西算”,还出了《数字中国建设规划》《算力基础设施高质量发展行动计划》这些文件,定了大方向。
地方也没闲着,北京、上海、浙江这些地方都出了具体方案,比如上海直接说“到2027年智算产业要破2000亿”,给企业吃了颗定心丸。
2. 技术终于“跟得上需求”
以前AI算力不够,很大原因是硬件和技术拖后腿。现在不一样了:
芯片方面:华为昇腾、寒武纪思元、壁仞BR100这些国产AI芯片,性能越来越接近国际水平,不用再完全依赖进口;
散热方面:以前数据中心靠风吹,又费电又降不了温,现在用“液冷”“浸没式冷却”,服务器直接泡在绝缘液体里,散热效率提了40%,还能支持更高密度的设备;
调度方面:现在能把分散的算力拼成“一个池”,比如你公司闲置的GPU,能通过云平台租给别人用,不浪费。
3. 产业需求“拦都拦不住”
2023年生成式AI(比如ChatGPT、国产的通义千问)一出来,直接把算力需求拉爆了——训练一个千亿参数的大模型,得用成千上万张GPU跑好几天。
而且不只是互联网公司要算力,现在金融行业用AI做风控、制造行业用AI质检、医疗行业用AI看片子,各个行业都开始抢算力,需求从“试试水”变成“必须有”。
4. 中小企业也能用得起了
以前算力是“土豪专属”——买一套高端服务器得花几百万,中小企业根本扛不住。
现在不一样了,云服务商、运营商都推出了“按需租赁”:比如按小时租GPU,高峰时用高端的,低谷时就退掉,成本一下降下来。
还有“算力交易”,就像买水电一样,用多少付多少,算力终于“普惠”了。
三、从“摸索”到“爆发”:AI算力的4个关键节点
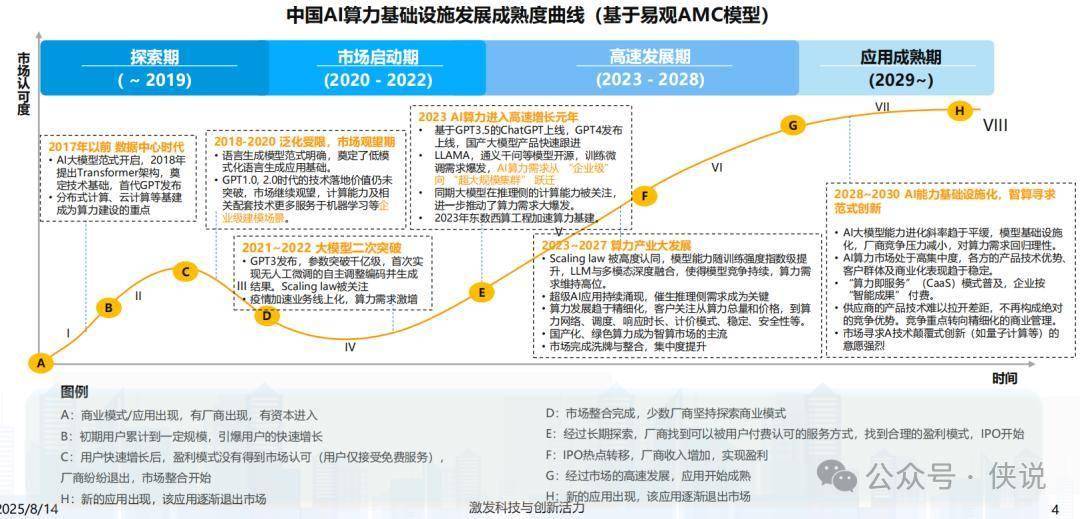
咱们捋捋时间线,就能明白现在的“高速增长”不是偶然:
2020年前:摸索期
2020-2022年:启动期
GPT3出来了,第一次实现“不用人工微调就能自己生成内容”,大家才发现“原来AI能这么强”。加上疫情倒逼业务线上化,算力需求开始涨,但还没到爆发的程度。
2023年至今:高速增长期
ChatGPT、GPT4陆续上线,国产大模型也跟着跑起来(比如LLAMA、通义千问开源),AI算力需求从“企业级”直接跳到“超大规模集群”——以前一个公司用几百张GPU就够了,现在训练一个大模型得用上万张。“东数西算”也在这时候加速,基建开始跟上需求。
2028年后:成熟期
到时候AI算力会更“精细”——大家不只会看“算力够不够多”,还会看“调度快不快”“稳不稳定”“安不安全”。可能会普及“按智能成果付费”,比如你用算力训练出一个模型,按模型带来的收益分成,而不是按时间付费。
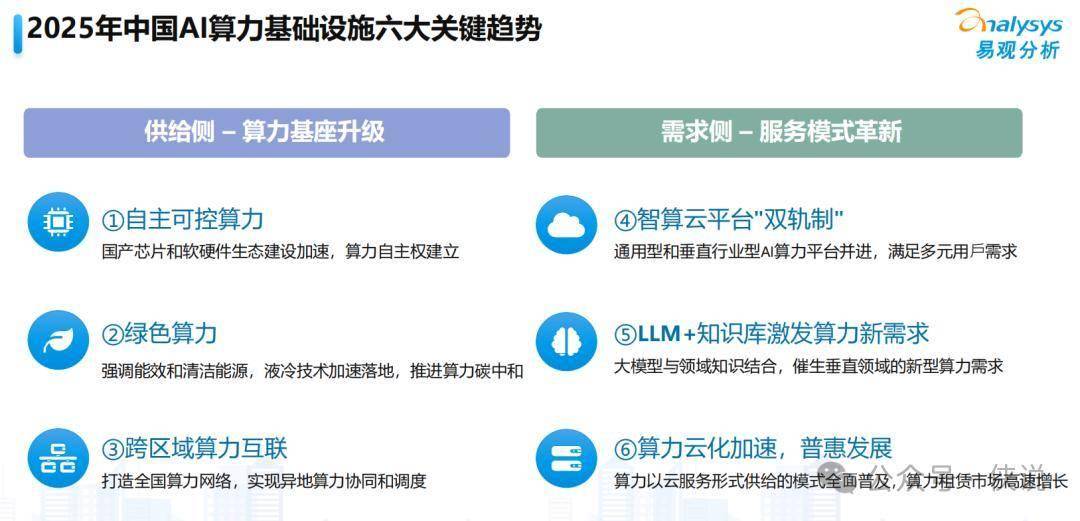
四、划重点!2025年AI算力的6个趋势
这部分是干货核心,不管你是做技术、搞业务,还是单纯好奇,这些趋势都会影响未来3-5年的AI发展。
1. 国产算力要“站起来”,不被卡脖子
现在国家把“算力自主可控”提到了很高的位置,目标很明确:2027年之前,智能算力里至少70%得是国产的。
比如上海临港已经在建“万卡规模”的国产智算集群,用的全是国产GPU和液冷技术;华为昇腾芯片已经在鹏城云脑这种超算中心大规模用了,寒武纪的思元芯片也能替代部分进口产品。
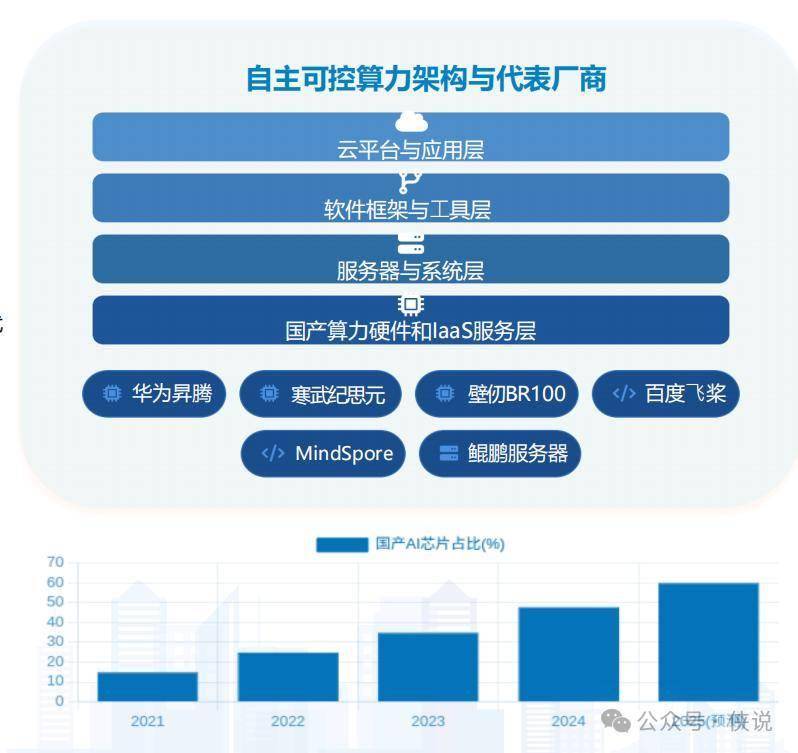
以后国产算力会越来越主流,不用再担心“别人断供”。
2. 算力要“绿色”,越省电越吃香
“双碳”目标下,算力中心不能再“大手大脚用电”了。
现在工信部要求新建大型数据中心的PUE(能源使用效率,越接近1越省电)必须降到1.3以下,头部智算中心甚至要求1.2以下。

怎么做到?一方面靠技术:液冷、浸没式冷却能把PUE降到1.2,比传统机房省30%电;另一方面靠能源:西部的算力中心用风电、水电,东部买绿电,上海有些智算园区已经有50%的电来自清洁能源了。
3. 全国算力“打通用”,东部西部互相帮
“东数西算”下一步要做的,就是让8个枢纽节点互联互通。比如现在已经有26个国家级骨干直联点,以后会更多,带宽也会扩,实现“全国算力自由流动”。
具体怎么用?东部白天算力紧张,就用西部的便宜绿色算力;西部晚上用电低谷,就用东部闲置的算力做数据备份。
比如宁夏的算力中心,已经能给东部的AI企业提供服务,既帮西部赚了钱,又满足了东部的需求。
4. 智算云平台分“两条路”,通用和垂直都要
以后的智算云平台会分成两种:
综合型平台:比如阿里云、华为云做的,相当于AI时代的“操作系统”——集成了数据处理、模型训练、推理部署全流程,不管你是做电商还是教育,都能在上面搭AI应用,门槛很低;
垂直型平台:专门服务某个行业,比如医疗AI平台会内置病历知识库、医学算法,金融AI平台会有风控模型,不用再从零开始搭,行业用户拿来就能用。

这两种平台会互相配合:综合平台给垂直平台提供基础能力,垂直平台的经验再反过来优化综合平台,最后满足不同用户的需求。
5. 大模型要“装知识”,更费算力但更有用
以前的大模型有时候会“瞎说话”(比如编造事实),现在要解决这个问题,就得给大模型“装知识库”——比如把公司的政策文档、行业的专业资料喂给模型,让它回答问题时有依据。
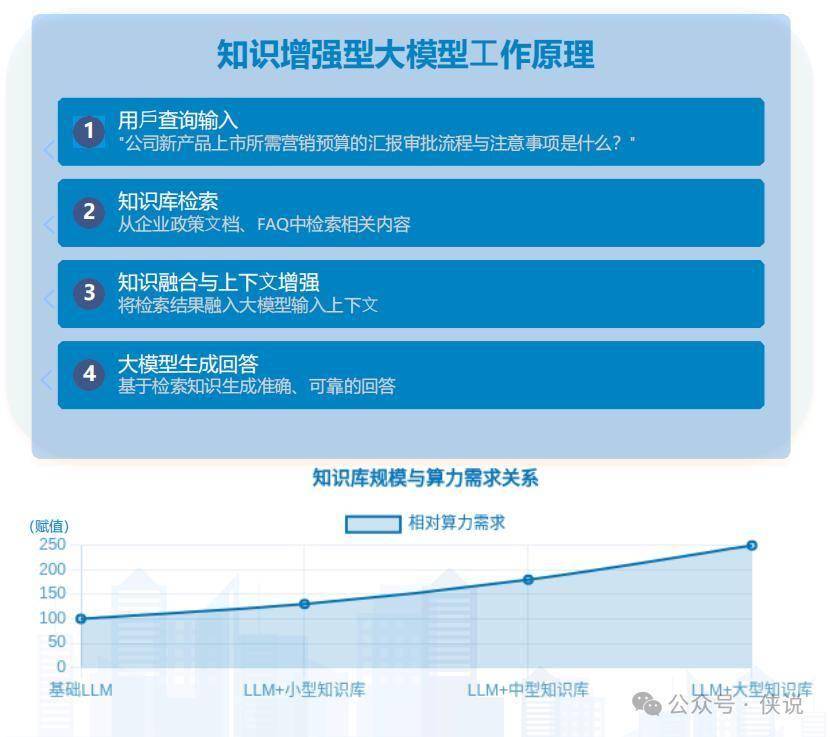
这种“大模型+知识库”的模式,会更费算力:比如企业部署一个带中型知识库的大模型,需要的算力是基础大模型的2-3倍。但好处也明显,比如你问“公司新产品营销预算怎么审批”,模型能直接翻内部文档,给出准确答案,不会再瞎编。
以后金融、医疗这些对准确性要求高的行业,都会这么做,也会催生更多高端算力需求。
6. 算力“云化”越来越普及,像水电一样随用随取
“算力即服务(CaaS)”会成为主流:以后没人会再花大价钱买服务器,而是直接从云端租。
比如九章智算云搞的“1度算力”,把算力标准化,不管你租的是哪的设备,都按统一标准计费,公平又方便。
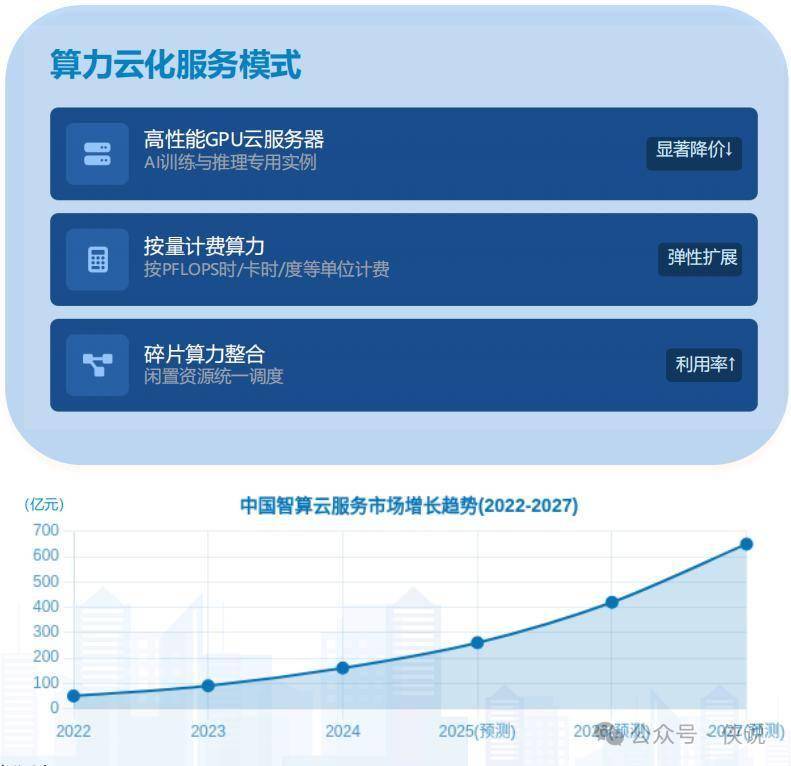
中小企业和个人开发者会受益最多:不用管机房、不用维护硬件,打开电脑就能用世界一流的算力。
以后云算力还会延伸到工厂车间、医院诊室这些边缘场景,形成“云-边-端”一体的供给体系,解决安全、带宽这些问题。
五、上海为什么能成为“AI算力优等生”?看这3点
最后拿上海举个例子,看看先进地区是怎么搞AI算力的,其他地方可以参考:
指标领先:截至2024年,上海的算力总规模已经到了“数十EFLOPS”,智能算力占比、投入强度这些关键指标都是全国第一梯队;
基建够硬:浦东张江有公共算力平台,临港新片区在建1.5万卡GPU的智算中心(里面有国内最大的单池万卡液冷集群),还有腾讯、阿里云、商汤共建的AIDC,形成了集群优势;
生态够全:有“书生·浦语”这些基础大模型,有专门做AI语料的公司(库帕思),还有近千亿的AI产业基金,聚集了商汤、华为、阿里这些头部企业,形成了“模型-数据-算力”的完整链条。
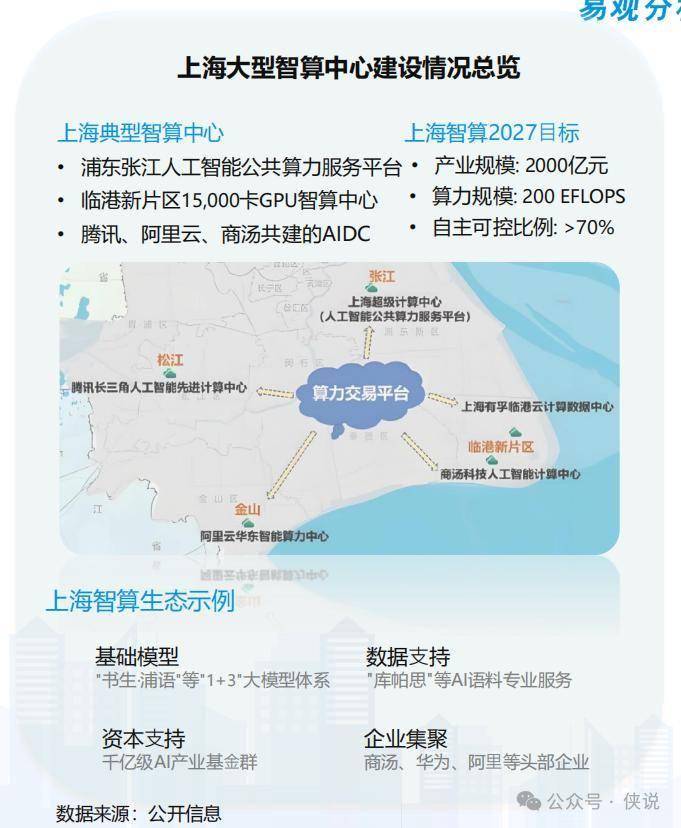
上海还定了2027年的目标:智算产业规模破2000亿,算力规模200 EFLOPS,自主可控占比超70%,野心不小。
六、不同人该怎么应对这场“算力革命”?
对政府来说:要统筹规划,别让各地盲目建数据中心;多给绿色算力、国产技术一些资金和税收优惠;开放政务、医疗这些公共数据,带动更多算力需求。
对企业来说:如果是提供算力的,就把平台做得更易用,多搞行业定制方案;如果是用算力的,优先租算力不用自建,把算力当成“生产要素”提前布局。
对普通人来说:以后不管是找工作还是创业,围绕“AI+算力”的方向(比如智算工程师、行业AI应用开发)都会是风口,多关注这个领域准没错。
本文太侠拆解自易观分析《2025年中国AI算力基础设施发展趋势洞察.pdf》。



