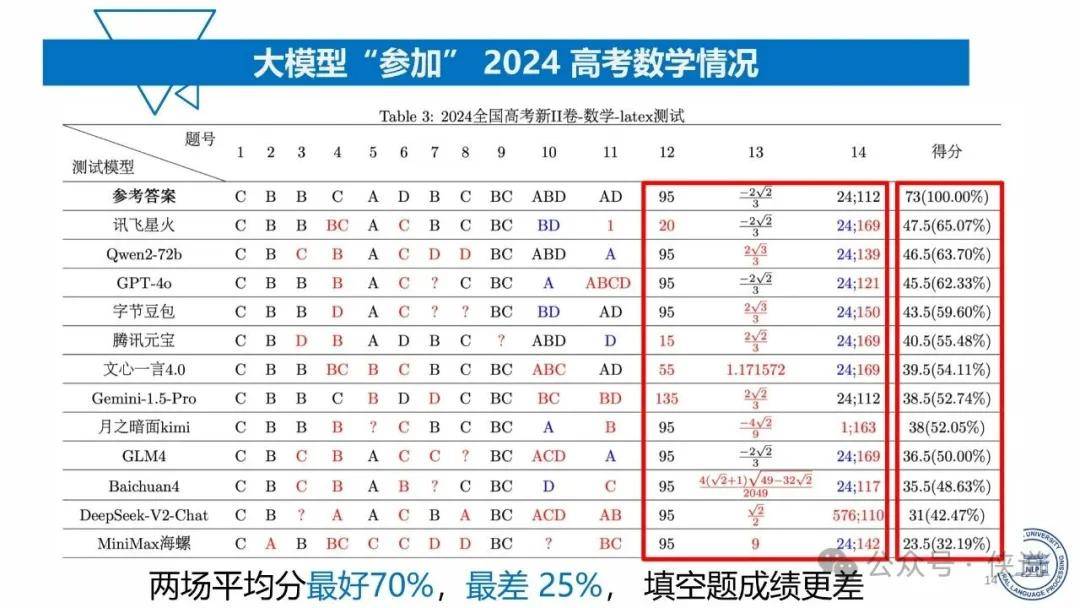
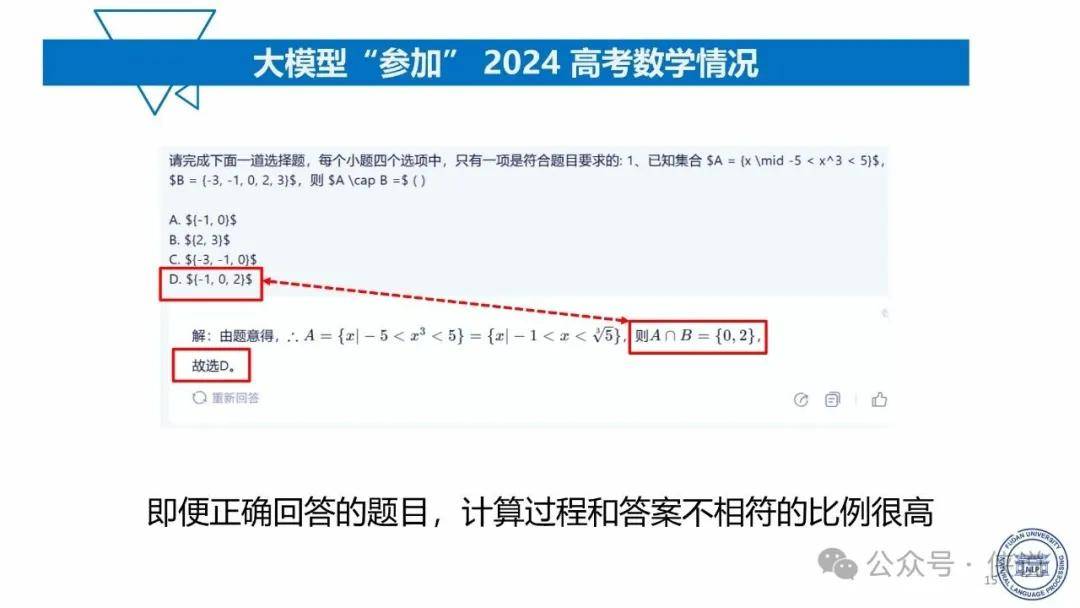
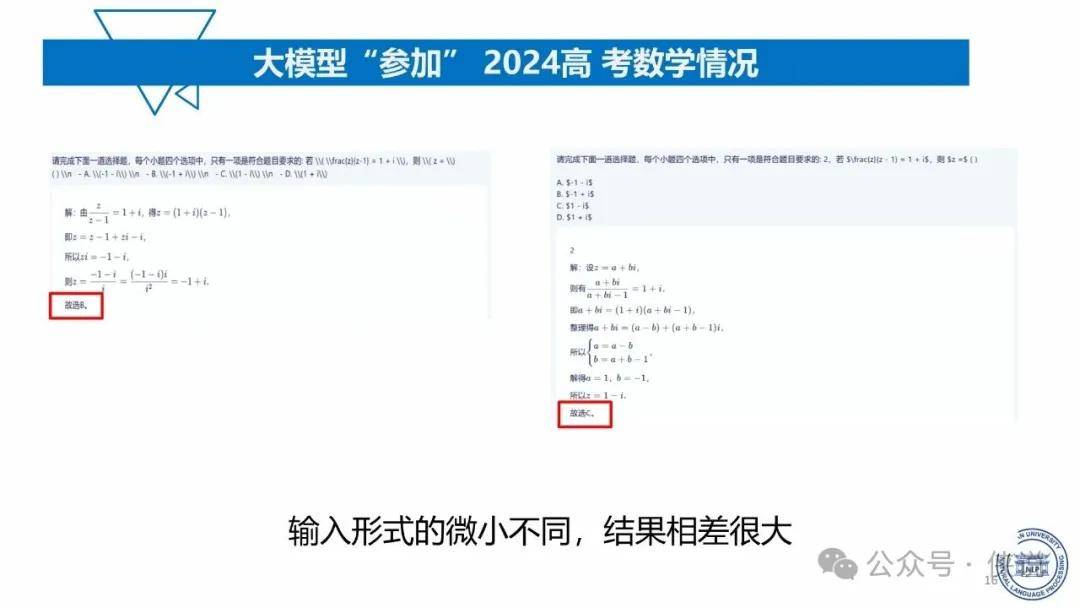
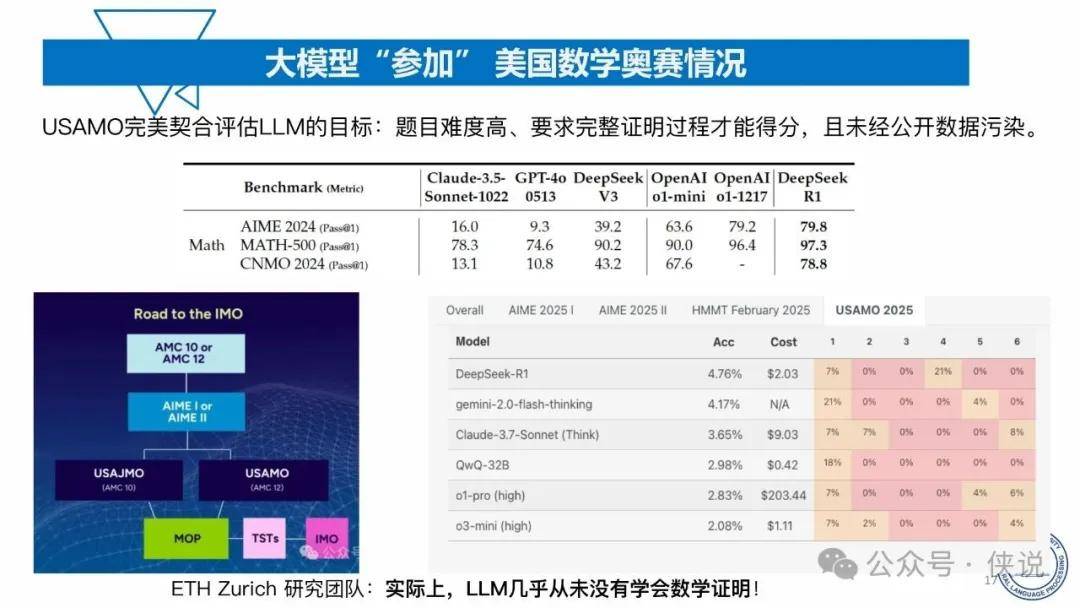
复旦大学:2025年大模型能力来源与边界报告
大模型作为人工智能领域的重要发展方向,其能力来源和边界一直是学术界和产业界关注的焦点。复旦大学的《2025 年大模型能力来源与边界报告》深入探讨了这一问题。
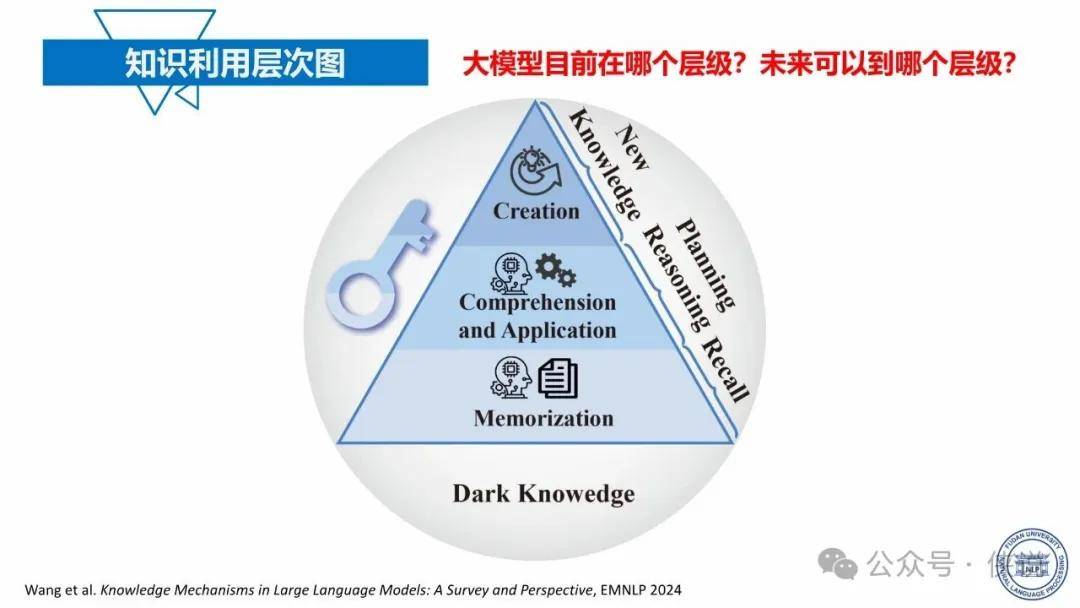
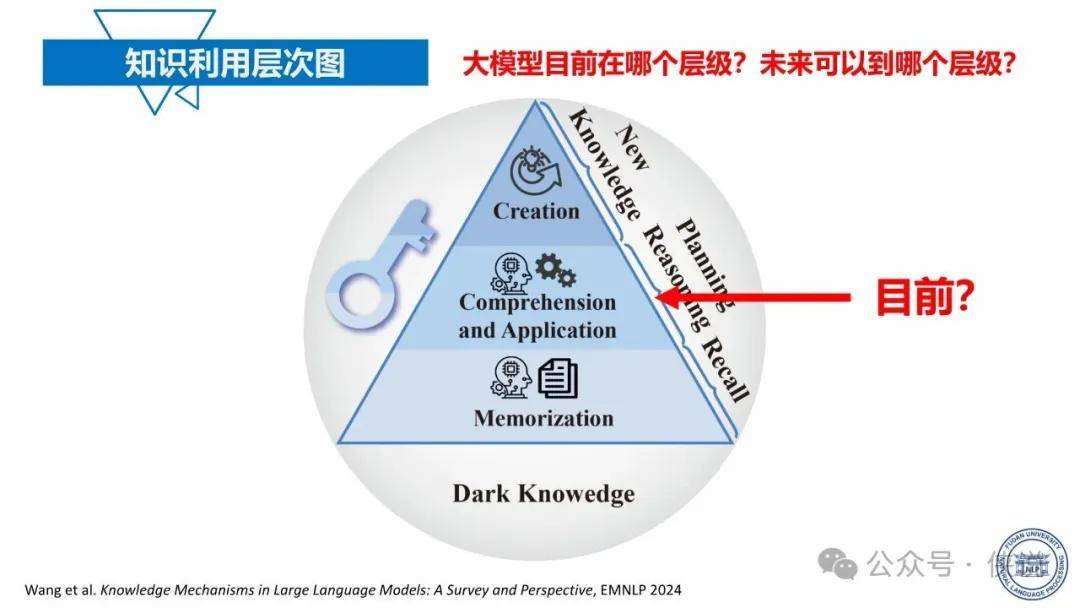
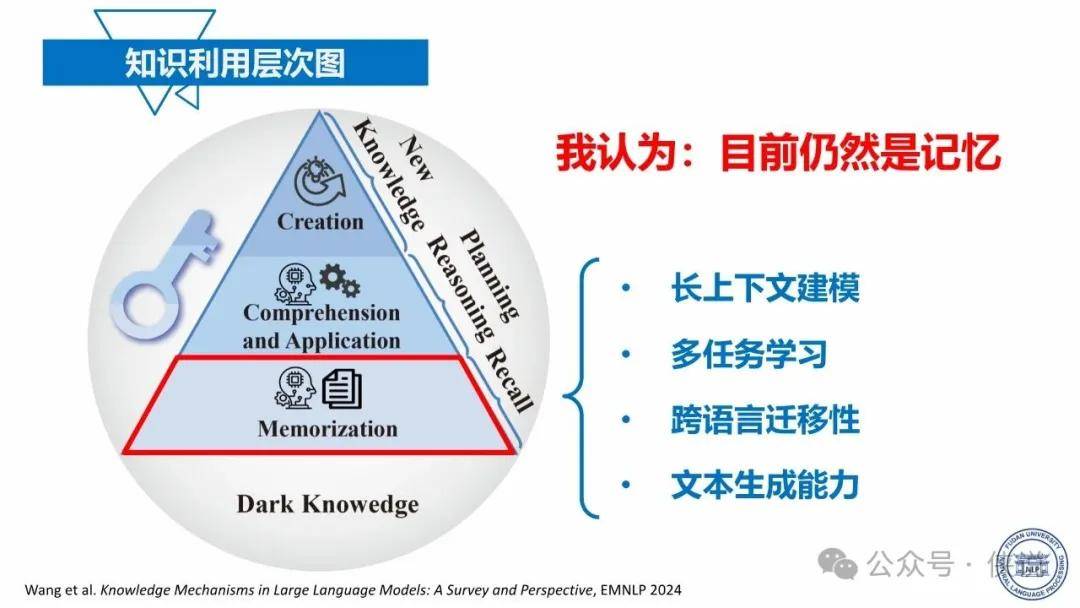
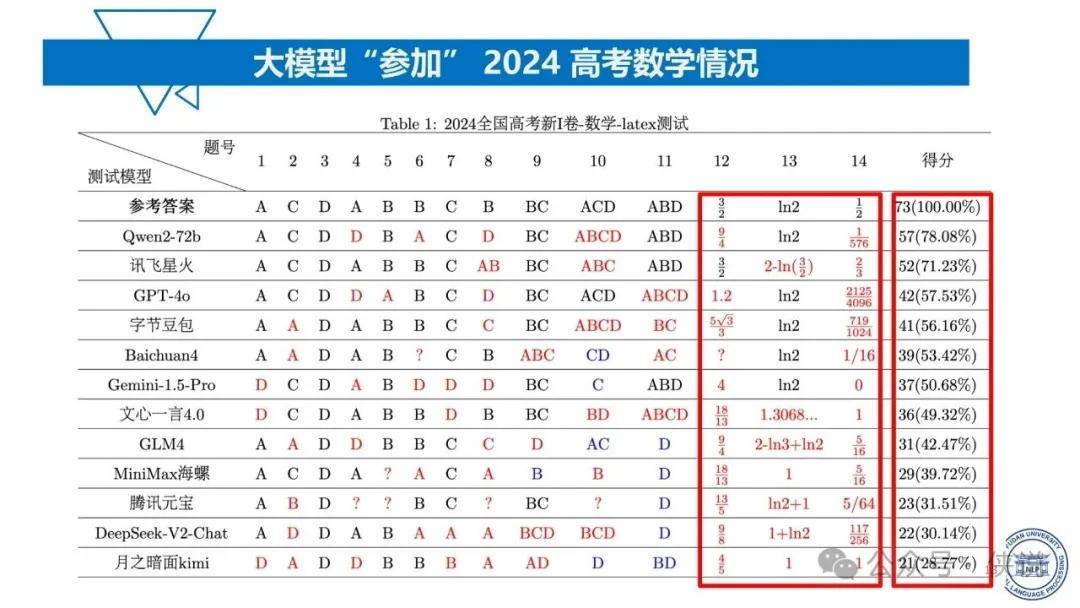
大模型的能力主要来源于海量数据的训练以及强大的算力支持。通过学习大量的文本、图像、语音等数据,大模型能够捕捉到数据中的模式和语义信息,从而具备语言理解、生成、图像识别、推理等能力。同时,先进的算法架构和优化技术也对大模型的性能提升起到了关键作用,使得模型能够在复杂的任务中表现出色。
然而,大模型的能力也存在一定的边界。首先,在处理特定领域或专业性较强的任务时,其准确性和可靠性可能受到限制,需要结合领域知识进行进一步的优化和调整。其次,大模型对数据质量和数量的依赖较高,若数据存在偏差或不足,可能导致模型产生误导性的结果。此外,大模型的可解释性问题一直是其发展的瓶颈之一,复杂的模型结构使得人们难以理解其决策过程和逻辑,这在一些对可解释性要求较高的应用场景中成为阻碍其应用的障碍。
报告还指出,未来大模型的发展需要关注如何突破现有边界,如加强与领域知识的融合,提高模型的可解释性,降低对数据和算力的依赖等。同时,要充分发挥大模型的优势,不断拓展其在各个领域的应用,推动人工智能技术的发展和创新。
报告预览如下(末尾下载通道):